
Exploring Redis High Availability
Recently, I’ve found myself using Redis for more of the projects that I work on. Redis can be used in a variety of ways. It provides functionality for queueing, set operations, bitmaps, streams, and so much more. Yet, most of my experience with Redis has been as a best-effort cache. Since it’s become a staple in my development, I figured it would be good to brush up on its operations.
In this post, I dive into the variety of ways Redis can be deployed. I’ll cover the benefits, tradeoffs, and even some uses for each deployment. Finally, I’ll describe the deployment that I recently put together.
What is Redis?
Redis is an open-source, in-memory database licensed under the BSD license. It has built-in replication, common eviction strategies, and even different levels of on-disk persistence. Redis also supports modules, which makes it easy to plug in new functionality and interact with native data types. For example, the RedisGraph module extends Redis by providing graph database capabilities. Due to the variety of data structures and its flexibility, it’s no wonder Redis has become as popular as it has.
How can Redis be deployed?
One of the big benefits to Redis is that it can be deployed in a variety of ways. We won’t dive into every deployment, but we will focus on the common patterns.
Replicated
The easiest deployment of Redis is a replicated architecture. In this deployment, Redis has a single, primary write point called a “master”. Any data written to this primary propagates to replicas asynchronously. The diagram below depicts how an application may interact with this deployment.
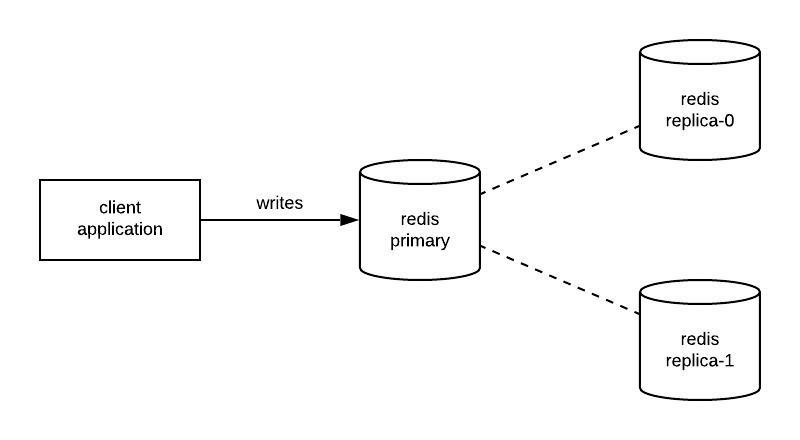
While the deployment is rather straightforward, there are a few things that we need to keep in mind. First, applications need to be able to track read-only and read-write connections. They could use a single connection, but that likely means that the primary handles every request. By using a single connection, your application makes no use of the replicas that you have in place. Second, this deployment has a single point of failure, the primary node. Should the primary node fail, applications can no longer write data to Redis.
This deployment works well for offline population. For example, maybe you have a background task that’s responsible for populating the cache. Meanwhile, your web service knows about the replicas and actively reads from them. Should the primary crash, your background process can simply wait for it to return.
Using Sentinel
To help alleviate the single primary node in the previous deployment, Redis provides Sentinel. Sentinel is a separate process that determines when a given primary node is no longer available. It does this by using a quorum to vote on member availability. When a member becomes unavailable, Sentinel is able to elect a new primary for the cluster. The diagram below depicts how an application may interact with this deployment.
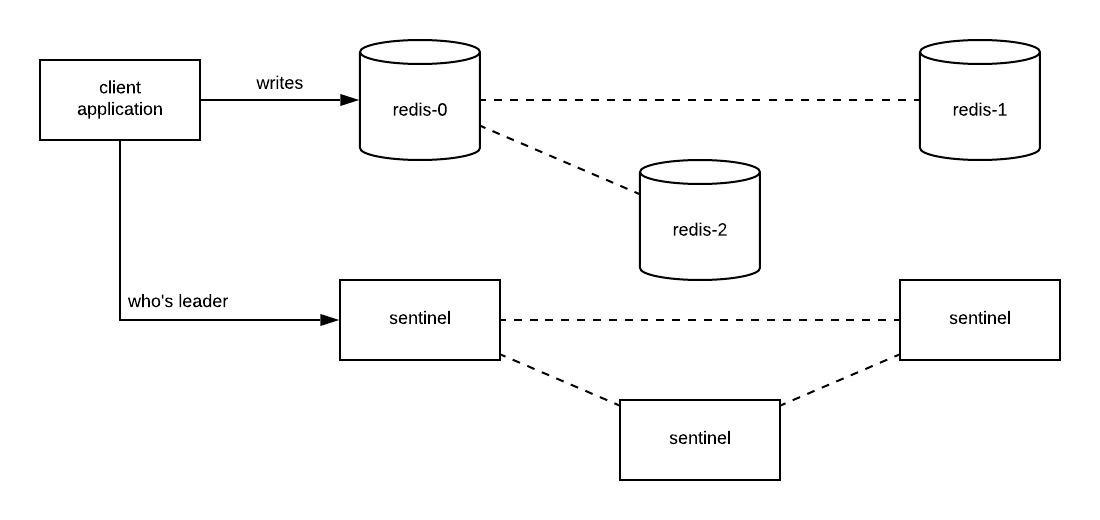
Similar to the last deployment, this approach has some downsides. When a client wants to write data to a Sentinel cluster, they first need to consult the Sentinel process. Sentinel reports to callers who the current primary in the cluster is. Then, clients will call the primary to write the data. As a result, clients need to be aware they are talking to a Sentinel cluster. This often requires additional configuration that few projects support.
Another risk to this deployment is a potential split-brain state during upgrades or node failures. A split-brain state happens when two nodes cannot come to an agreement. This case is less likely if you manage Sentinel deployments separately from Redis. If you run them in the same pod or on the same host, the likelihood of this scenario increases. To illustrate let us consider the above example.
- Suppose we upgrade our cluster and
redis-0is taken down. - Sentinels detect that the pod is no longer available and start figuring out a new primary.
- The sentinel for
redis-1votes thatredis-2should be the new primary. - The sentinel for
redis-2votes thatredis-1should be the new primary. - With a quorum of
2, the instances are unable to come to consensus. - Steps 2 through 5 repeat until the instances reach a quorum.
Unfortunately, this is how Bitnami configures the deployment of Sentinel in their redis Helm chart. While
split-brains can occur, they may not be as common as you may think. Still, it’s something you need to account for in
your deployment.
Redis Cluster
Redis Cluster is popular amongst those using Redis for a large amount of data. It shards data across the instances in the cluster, thus reducing the resource requirements of each individual node. Redis does this by hashing the provided key into a slot. Slots are distributed across the primaries in the cluster, often in chunks. The diagram below illustrates how an application might interact with members of a Redis Cluster.
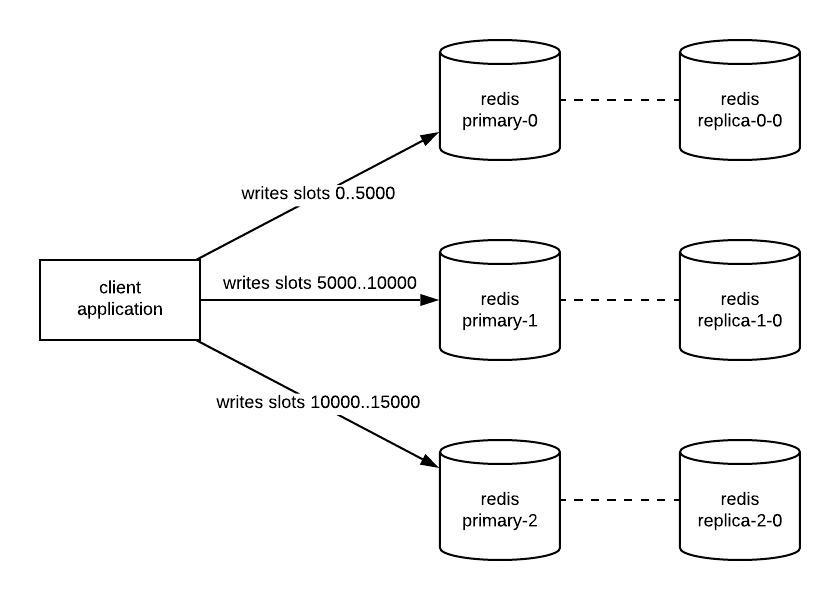
Similar to the Sentinel deployment, applications need to be aware they are speaking to a Redis Cluster. This is due to how Redis Cluster handles its sharding. Clients are responsible for hashing keys to determine which slot they write to. Then, clients write to the instance responsible for the associated slot. This will allow clients to perform a subset of operations, even in the event of a partial cluster outage.
Clustering with Envoy
An alternative to using Redis Cluster would be to cluster using Envoy. Envoy is a well-known, well-supported, network proxy open-sourced by Lyft. It supports many protocols including HTTP, gRPC, MongoDB, Redis, and more. When using Envoy to cluster instances, envoy handles partitioning the keyspace on behalf of Redis. This means the underlying Redis instances shouldn’t have clustering enabled.
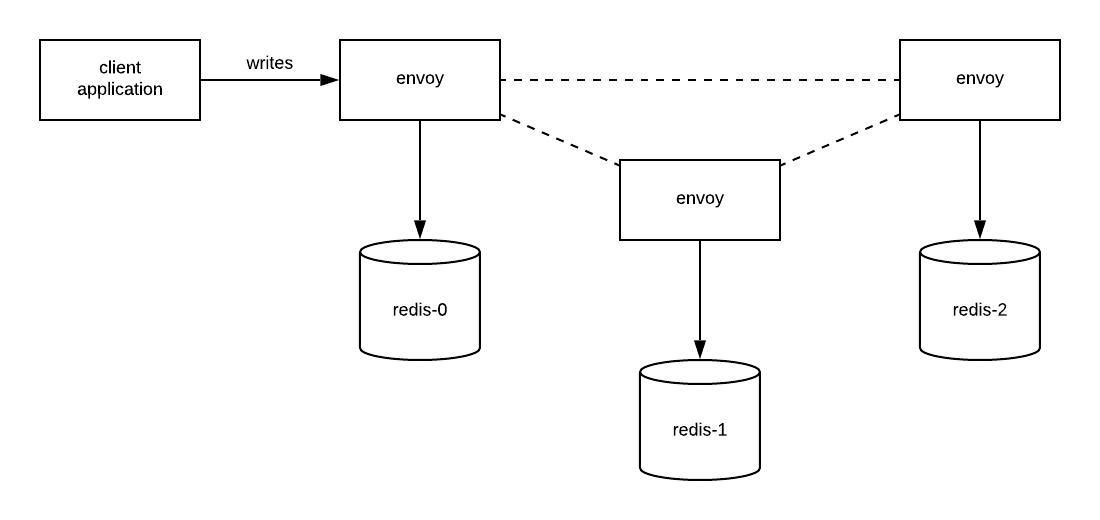
In this deployment, Envoy favors availability and partition tolerance over consistency. This makes it ideal for a
best-effort cache, but not great for more stateful systems. You might consider setting an LRU eviction policy for Redis
to ensure stale, unused data is pruned first. One nice thing about this deployment is that clients can speak to any
envoy instance in the cluster. This drastically simplifies the logic on the callers’ end when compared to Redis
Cluster.
2022-03-21 Edit
I’ve written up a Redis Helm Chart that makes it easy to deploy a Redis cluster using this pattern. Instead of running Envoy as a sidecar to the Redis server, client applications must embed it into their own application. My helm chart provides a simple function for doing so. For a reference on how to do this, see the Registry Helm Chart as an example.
My deployment
While these approaches can work great, I often found myself wanting something a little different. Ideally, I wanted a deployment that:
- Improves the availability of the replicated deployment
- Improves the stability of the sentinel deployment
- Maintains the simplicity of the replicated deployment
- Maintains the consistency of the Redis deployments
Such a deployment would improve task and queue-based systems like Celery in python or Machinery in go. Payloads in these systems tend to be small, relatively short-lived, and/or backed up elsewhere. This means we rarely need to shard data across nodes.
As I contemplated how to do this, I kept my runtime environment in mind. Kubernetes provides many capabilities to
engineers. For example, adding leader election to a system is relatively easy to do in Go. The client-go library
provides a pre-built leaderelection package. This can automate watching a Lease for changes and periodically
attempting to claim leadership. This had given me an idea for a sidecar.
- The sidecar would use the Lease API to determine leadership in the cluster.
- When an election occurs, the sidecar is responsible for updating the topology of the Redis cluster.
- Each sidecar acts independently, removing the need for coordination beyond the initial election.
- Each sidecar takes appropriate steps to handle the change in leadership gracefully.
- The current leader pauses writes and waits for the newly elected leader to catch up.
- The newly elected leader waits for syncs to complete before attempting to promote itself to leader.
- All other followers swap over to replicating from the new leader.
- Once the topology of the cluster has been updated, the sidecar of the newly elected updates a Kubernetes
Endpoint.- This Endpoint can be used by clients to guarantee requests get sent to the leader.
- A separate service can be used to allow reads to any node in the cluster.
Such a system can be seen below.
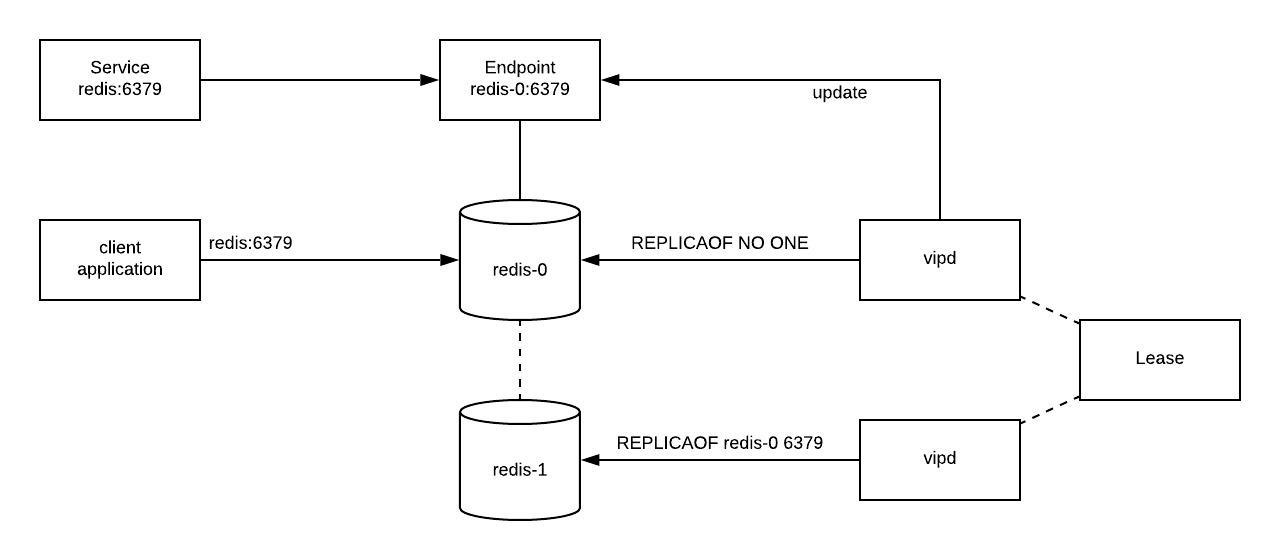
A nice thing about this deployment is that the mitigation techniques are similar to that of the sentinel deployment. While we aren’t using the sentinel to perform the election process, we are doing more or less the same thing. A benefit to this deployment over sentinel is that we remove the call to discover the current leader. Instead, clients get a stable address they can dial and always reach a leader, even during rolling upgrades.
In the few tests I ran, I had seen failover times of 6 to 10 seconds. Definitely still working out some tuning, but all in all, I’m satisfied with how it came out. For now, I’m going to keep the project closed source. If you’re interested in chatting through this a bit more feel free to reach out.
Anyway, thanks for checking in. I know it’s been a while. I hope you learned something while you were here. Thanks for reading!