
Gracefully Degrading Functionality Using Status
In a previous blog post, we described how to use our Status library to create a robust health check for your applications. In this follow-up, we show how you can check and degrade your application during an outage by:
- short-circuiting code paths of your application
- removing a single application instance from a data center load balancer
- removing an entire data center from rotation at the DNS level
Evaluating application health The Status library allows you to perform two different types of checks on a system — a single dependency check and a system-wide evaluation. A dependency is a system or service that your system requires in order to function.
During a single dependency check, the AbstractDependencyManager uses an evaluate method that takes the dependency’s ID and returns a CheckResult.
A CheckResult includes:
- the health of the dependency
- some basic information about the dependency
- the time it took to evaluate the health of the dependency
A CheckResult is a Java enum that is one of OK, MINOR, MAJOR, or OUTAGE.
The OUTAGE status indicates that the dependency is not usable.
final CheckResult checkResult = dependencyManager.evaluate("dependencyId");
final CheckStatus status = checkResult.getStatus();The second approach to evaluating an application’s health is to look at the system as a whole.
This gives you a high-level overview of how the entire system is performing.
When a system is in OUTAGE, this indicates that the instance of an application is not usable.
final CheckResultSet checkResultSet = dependencyManager.evaluate();
final CheckStatus systemStatus = checkResultSet.getSystemStatus();If a system is unhealthy, it’s often best to short circuit requests made to the system and return an HTTP status code 500 (“Internal Server Error”). In the example below, we use an interceptor in Spring to capture the request, evaluate the system’s health, and respond with an error in the event that the application is in an outage.
public class SystemHealthInterceptor extends HandlerInterceptorAdapter {
private final DependencyManager dependencyManager;
@Override
public boolean preHandle(
final HttpServletRequest request,
final HttpServletResponse response,
final Object handler
) throws Exception {
final CheckResultSet checkResultSet = dependencyManager.evaluate();
final CheckStatus systemStatus = checkResultSet.getSystemStatus();
switch (systemStatus) {
case OUTAGE:
response.setStatus(HttpStatus.INTERNAL_SERVER_ERROR.value());
return false;
default:
break;
}
return true;
}
}Comparing the health of dependencies
CheckResultSet and CheckResult have methods for returning the current status of the system or the dependency, respectively. Once you have CheckStatus, there are a couple of methods that allow you to compare the results.
isBetterThan() determines if the current status is better than the provided status. This is an exclusive comparison.
CheckStatus.OK.isBetterThan(CheckStatus.OK) // evaluates to false
CheckStatus.OK.isBetterThan(/* any other CheckStatus */) // evaluates to trueisWorseThan() determines if the current status is worse than the provided status. Again, this operation is exclusive.
CheckStatus.OUTAGE.isWorseThan(CheckStatus.OUTAGE) // evaluates to false
CheckStatus.OUTAGE.isWorseThan(/* any other CheckStatus */) // evaluates to trueThe isBetterThan() and isWorseThan() methods are great tools to check for a desired state of an evaluated dependency.
Unfortunately, these methods do not offer enough control to produce a graceful degradation.
Either the system was healthy, or it was in an outage.
To better control the graceful degradation of our system, two additional methods were needed.
noBetterThan() returns the unhealthier of the two statuses.
CheckStatus.MINOR.noBetterThan(CheckStatus.MAJOR) // returns CheckStatus.MAJOR
CheckStatus.MINOR.noBetterThan(CheckStatus.OK) // returns CheckStatus.MINORnoWorseThan() returns the healthier of the two statuses.
CheckStatus.MINOR.noWorseThan(CheckStatus.MAJOR) // returns CheckStatus.MINOR
CheckStatus.MINOR.noWorseThan(CheckStatus.OK) // returns CheckStatus.OKDuring the complete system evaluation, we use a combination of these methods and the Urgency#downgradeWith() methods to gracefully degrade our application’s health.
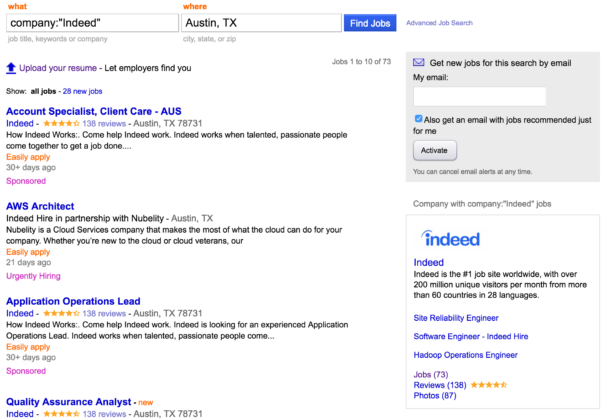
By having the ability to inspect the outage state, engineers can dynamically toggle feature visibility based on the health of its corresponding dependency. Suppose that our service that provides company information was unable to reach its database. The service’s health check would change its state to MAJOR or OUTAGE. Our job search product would then omit the company widget from the right rail on the search results page. The core functionality that helps people find jobs would be unaffected.
Healthy
Unhealthy (Gracefully)
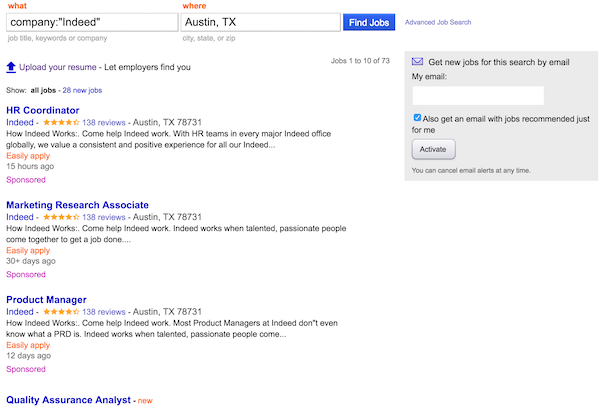
Status offers more than just the ability to control features based on a service’s health. We also use it to control access to instances of our front end web applications. When an instance is unable to service requests, we remove it from the load balancer until it is healthy again.
Instance level failovers
Generally, running multiple instances of your application in production is highly recommended. This helps keep your system resilient by allowing it to continue to handle requests even if a single instance of your application crashes. These instances of your application can live on a single machine, multiple machines, and even in multiple data centers.
The Status library lets you configure your load balancer to remove an instance if it becomes unhealthy. Consider the following basic example within a single data center.
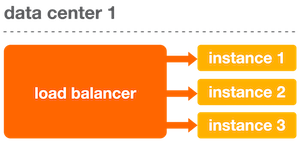
When all of the applications within a single data center are healthy, the load balancer distributes requests among them evenly. To determine if an application is healthy, the load balancer sends a request to the health check endpoint and evaluates the response code.
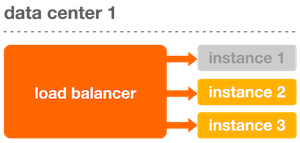
When an instance becomes unhealthy, the health check endpoint returns a non-200 status code, indicating that it should no longer receive traffic. The load balancer then removes the unhealthy instance from rotation, preventing it from receiving requests.
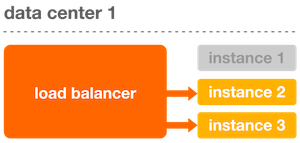
When instance 1 is removed from rotation, the other instances within a data center start to receive instance 1’s traffic. Within each data center, we provision enough instances so that we can handle traffic even if some of the instances go down.
Data center level failovers
Before a request is even sent to a data center, our domain (e.g. www.indeed.com) is resolved to an IP address using DNS. We use Global Server Load Balancer (GSLB) that allows us to geographically distribute traffic across our data centers. After the GSLB resolves the domain to the IP address of the nearest available data center, the data center load balancer then routes and fails over traffic as described above.
What if an entire data center can no longer service requests? Similar to the single instance approach, GSLB constantly checks each of our data centers for their health (using the same health check endpoint). When GSLB detects that a single data center can no longer service requests, it fails requests over to another data center and removes the unhealthy data center from rotation. Again, this helps keep the site available by ensuring that requests can be processed, even during an outage.
As long as a single data center remains healthy, the site can continue to service requests. For users that hit unhealthy data centers, this just looks like a slower web page load. While not ideal, the experience is better than an unprocessed request.
The last scenario is a complete system outage. This occurs when every data center becomes unhealthy and can no longer service requests. Engineers try to avoid this situation like the plague.
When Indeed encounters complete system outages, we reroute traffic to every data center and every instance. This policy, known as “failing open,” allows for graceful degradation of our system. While every instance may report an unhealthy state, it is possible that an application can perform some work. And being able to perform some work is better than performing no work.
Status works for Indeed and can work for you
The Status library is an integral part of the systems that we develop and run at Indeed. We use Status to:
- quickly fail over application instances and data centers
- detect when a deploy is going to fail before the code reaches a high traffic data center
- keep our applications fast by failing requests quickly, rather than doing work we know will fail
- keep our sites available by ensuring that only healthy instances of our applications service requests
To get started with Status, read our quick start guide and take a look at the samples. If you need help, you can reach out to us on GitHub or Twitter.